.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Die Diskussion Spark vs. Hadoop ist oft irreführend. Es geht nicht darum, einen Sieger zu küren, sondern zu verstehen, wann welche Technologie die richtige Wahl ist und wie sie optimal zusammenspielen. Die Entscheidung zwischen beiden Frameworks ist eine strategische Weichenstellung, die Performance, Kosten und die Zukunftsfähigkeit Ihrer Datenarchitektur direkt beeinflusst.
Für schnelle, iterative Prozesse wie Machine Learning oder Echtzeitanalysen ist Spark mit seiner In-Memory-Verarbeitung die technologisch überlegene Wahl. Geht es jedoch um die kosteneffiziente Speicherung und lineare Verarbeitung riesiger Datenmengen im Batch-Verfahren, hat Hadoop nach wie vor seine Berechtigung, insbesondere als robuste Datenspeicherlösung.
Die Entscheidung zwischen Apache Spark und Apache Hadoop hängt von den konkreten Anforderungen Ihres Projekts ab. Es ist weniger eine Frage der grundsätzlichen Überlegenheit als die Wahl des passenden Werkzeugs für eine spezifische Aufgabe. In der Praxis führt die Debatte „Spark vs. Hadoop“ häufig zu einer „Spark mit Hadoop“-Architektur, die die Stärken beider Systeme kombiniert.
Hadoop, das ältere der beiden Frameworks, wurde entwickelt, um riesige Datenmengen kostengünstig auf Standard-Hardware zu speichern und zu verarbeiten. Seine Architektur basiert auf zwei Kernkomponenten:
Spark wurde als schnellere und flexiblere Alternative zu Hadoops MapReduce-Komponente entwickelt. Sein entscheidender Vorteil ist die In-Memory-Verarbeitung: Daten werden im Arbeitsspeicher gehalten, anstatt nach jedem Schritt auf die Festplatte geschrieben zu werden. Dies reduziert die Latenz drastisch und beschleunigt iterative Prozesse massiv.
"Der wesentliche Unterschied im direkten Vergleich ist die Performance. Spark wurde gezielt entwickelt, um die Latenzprobleme von MapReduce zu lösen. Das macht es zur ersten Wahl für zeitkritische Analysen, Machine-Learning-Anwendungen und interaktive Abfragen."
Diese Gegenüberstellung fasst die wichtigsten Unterschiede zusammen und zeigt, für welche Anwendungsfälle die Frameworks jeweils optimiert sind.
Benchmarks belegen, dass Apache Spark Hadoop in Sachen Geschwindigkeit um das bis zu 100-fache übertreffen kann. Während Spark Daten im Arbeitsspeicher verarbeitet, schreibt Hadoops MapReduce Zwischenergebnisse auf die Festplatte, was die Prozesse spürbar verlangsamt.
Wenn Sie tiefer in die Performance-Unterschiede eintauchen möchten, finden Sie dort weitere Details. Für CTOs und Tech-Leads bedeutet dies in der Praxis: Spark ist die bevorzugte Engine für alle Aufgaben, bei denen Performance entscheidend ist. Hadoop bleibt jedoch eine extrem solide und kosteneffiziente Basis für die reine Datenspeicherung.
Wer sich zwischen Spark und Hadoop entscheiden muss, sollte die grundlegende Datenverarbeitung der Systeme verstehen. Genau hier, in der Architektur, liegen die Unterschiede, die sich direkt auf Performance, Kosten und Anwendungsfälle auswirken.
Vereinfacht gesagt: Hadoop wurde für die robuste, festplattenbasierte Verarbeitung riesiger Datenmengen konzipiert, während Spark von Beginn an auf Geschwindigkeit durch In-Memory-Verarbeitung setzte.

Hadoops Architektur basiert auf dem Hadoop Distributed File System (HDFS) für die Speicherung und MapReduce für die Verarbeitung. Dieser Aufbau macht es extrem resilient und kostengünstig für die Sicherung und Verarbeitung gewaltiger Datenmengen auf Standard-Hardware.
Das Herzstück von Hadoop ist das MapReduce-Modell, ein klassisches Verfahren für die Stapelverarbeitung (Batch Processing). Jede Aufgabe wird in zwei Phasen zerlegt:
Der entscheidende Punkt ist, dass MapReduce die Zwischenergebnisse nach jedem Schritt auf die Festplatte schreibt. Dieser Lese- und Schreibvorgang garantiert eine enorme Fehlertoleranz: Fällt ein Knoten aus, kann die Verarbeitung von einem gespeicherten Punkt neu gestartet werden. Genau dieser Mechanismus führt aber auch zu einer spürbaren Latenz.
"Für lineare, nicht zeitkritische ETL-Prozesse oder die Archivierung von Petabytes an Daten ist Hadoops Architektur nach wie vor eine sehr stabile und wirtschaftliche Lösung. Die Fehlertoleranz auf Festplattenebene ist hier ein entscheidender Vorteil."
Dieser robuste Ansatz erklärt, warum Hadoop in vielen Big-Data-Infrastrukturen tief verankert ist. Allein in Deutschland setzen laut einer Analyse 539 Unternehmen auf Apache Hadoop, was seine anhaltende Bedeutung in Branchen wie der Automatisierungsmaschinenfertigung oder der Pharmaindustrie zeigt. Mehr zur Verbreitung von Hadoop in deutschen Unternehmen erfahren Sie auf theirstack.com.
Apache Spark wurde gezielt entwickelt, um die Geschwindigkeitsnachteile von MapReduce auszugleichen. Die Kerntechnologie dahinter sind die Resilient Distributed Datasets (RDDs), eine Abstraktion, die es erlaubt, Daten verteilt im Arbeitsspeicher (RAM) eines Clusters zu halten.
Anders als Hadoop vermeidet Spark unnötige Festplattenzugriffe. Solange genügend RAM zur Verfügung steht, laufen alle Zwischenschritte einer Berechnung direkt im Speicher ab. Nur das Endergebnis wird auf einem persistenten Speicher gesichert.
Dieser In-Memory-Ansatz bringt massive Performance-Vorteile, vor allem bei:
Die Fehlertoleranz löst Spark elegant über die „Lineage“ (Abstammungslinie) der RDDs. Spark merkt sich die Transformationen, durch die ein Datensatz entstanden ist. Geht ein Teil der Daten im Speicher verloren, kann Spark ihn aus den Quelldaten und den gespeicherten Schritten schnell neu berechnen – ohne auf langsame Festplatten-Checkpoints angewiesen zu sein.
Ein weiterer Vorteil ist Sparks Flexibilität. Das Framework ist nicht an HDFS gebunden, sondern kann Daten aus diversen Quellen lesen, darunter Cloud-Speicher wie Amazon S3 oder Azure Blob Storage. Für eine tiefere Einordnung von Spark in die moderne Datenlandschaft empfehlen wir unseren Leitfaden zur Big-Data-Analyse.
Aus technischer Sicht bedeutet das: Spark-Cluster benötigen in der Regel mehr Arbeitsspeicher, was die Hardwarekosten erhöhen kann. Im Gegenzug erhält man eine extrem vielseitige und agile Datenverarbeitung, die für moderne Echtzeitanforderungen oft unerlässlich ist.
Theoretische Benchmarks sind eine Sache, aber die wahre Leistungsfähigkeit einer Technologie zeigt sich im praktischen Einsatz. Genau hier, in konkreten Geschäftsszenarien, wird der Unterschied zwischen Spark vs. Hadoop greifbar.
Der oft zitierte Geschwindigkeitsvorteil von Spark ist keine graue Theorie, sondern wird in alltäglichen Big-Data-Anwendungen, die auf geringe Latenz angewiesen sind, schnell zum entscheidenden Faktor.

Nehmen wir das Training von Machine-Learning-Modellen. Diese Prozesse sind von Natur aus iterativ – dieselben Daten werden immer wieder durchlaufen, um die Parameter eines Modells zu verfeinern. Hadoops MapReduce schreibt die Zwischenergebnisse nach jeder Runde auf die Festplatte, was den Prozess enorm verlangsamt. Spark hingegen behält die Daten im Arbeitsspeicher, wodurch Trainingszeiten von Stunden auf Minuten reduziert werden können.
Ein ähnliches Bild zeigt sich bei interaktiven SQL-Abfragen. Wenn Datenanalysten spontane Ad-hoc-Analysen durchführen, benötigen sie Ergebnisse in Sekunden, nicht Minuten. Mit Spark SQL können sie komplexe Abfragen auf Terabytes an Daten ausführen und erhalten die Antworten nahezu in Echtzeit.
Sparks beeindruckende Geschwindigkeit hat ihren Preis. Die In-Memory-Verarbeitung stellt hohe Anforderungen an den Arbeitsspeicher (RAM). Um die Performance-Vorteile voll auszuspielen, muss der Spark-Cluster mit genügend RAM ausgestattet sein, um die aktiven Datensätze im Speicher halten zu können.
Dies führt direkt zu den Hardwarekosten. Server mit viel RAM sind teurer als Standardmaschinen, die primär auf günstigen Festplattenspeicher ausgelegt sind.
"Für Entscheider läuft es auf einen klaren Trade-off hinaus: Ist der Performance-Gewinn durch Spark die höheren Hardwarekosten wert? Die Antwort darauf gibt allein der konkrete Anwendungsfall."
Hadoop MapReduce ist hier genügsamer. Es wurde für den Betrieb auf kostengünstiger Standardhardware entwickelt und kann Datenmengen verarbeiten, die weit über die Kapazität des verfügbaren RAMs hinausgehen. Das macht es für bestimmte Szenarien zur wirtschaftlicheren Wahl.
Machen wir es konkret und betrachten drei typische Anwendungsfälle:
Letztendlich ist die Performance-Frage immer kontextabhängig. Während Spark in den meisten modernen Anwendungsfällen die Nase vorn hat, bleibt Hadoop eine grundsolide und kostengünstige Alternative für klassische Batch-Verarbeitung, bei der Zeit keine entscheidende Rolle spielt. Seine Fähigkeit, auch bei riesigen Datenmengen zuverlässig zu skalieren, ist ein nicht zu unterschätzender Vorteil. Wenn Sie tiefer einsteigen wollen, wie die Skalierbarkeit von Software die Systemarchitektur prägt, finden Sie in unserem Artikel wertvolle Einblicke. Eine ehrliche Abwägung zwischen Performance-Anforderungen und Budget ist der Schlüssel, um teure Fehlinvestitionen zu vermeiden und eine zukunftssichere Big-Data-Plattform aufzubauen.
Jede Technologie ist nur so gut wie ihr Einsatzgebiet. Die Frage Spark vs. Hadoop lässt sich am besten beantworten, indem man konkrete Anwendungsfälle analysiert und mit den eigenen Geschäftszielen abgleicht. Die Wahl des falschen Werkzeugs führt schnell zu unnötigen Kosten oder Performance-Engpässen.
Am Ende geht es darum, die Stärken beider Frameworks zu kennen und sie genau dort einzusetzen, wo sie den größten Nutzen bringen. Oft ist die beste Lösung kein Entweder-oder, sondern eine kluge Kombination aus beiden Systemen.

Hadoop bleibt die erste Wahl für Szenarien, bei denen geringe Kosten und robuste Speicherung wichtiger sind als die reine Verarbeitungsgeschwindigkeit. Seine festplattenbasierte Architektur ist perfekt für lineare, massive Batch-Jobs optimiert.
Hier spielt Hadoop seine Stärken voll aus:
Diese Stärke im Umgang mit riesigen Datenmengen erklärt auch Hadoops globale Bedeutung. Während Nordamerika den Hadoop-Markt dominiert, wächst Europa stark, insbesondere in den Finanz- und IT-Sektoren. Weltweit wird der Markt für Hadoop-Big-Data-Analytics im Jahr 2024 auf 12,86 Milliarden US-Dollar geschätzt, was das anhaltende Vertrauen in die Technologie unterstreicht.
Apache Spark wurde gezielt entwickelt, um die Latenzprobleme von MapReduce zu beheben. Es glänzt überall dort, wo Geschwindigkeit erfolgskritisch ist. Seine In-Memory-Fähigkeiten machen Analysen und Entscheidungen in Quasi-Echtzeit erst möglich.
"Der entscheidende Vorteil von Spark liegt in seiner Fähigkeit, komplexe, iterative Aufgaben schnell auszuführen. Dies macht es zum idealen Werkzeug für Machine Learning, interaktive Analysen und Echtzeit-Anwendungen."
Typische Beispiele für Spark-Anwendungen sind:
Um die richtigen Anwendungsfälle für Big-Data-Technologien im eigenen Unternehmen zu identifizieren und erfolgreich umzusetzen, kann externes Fachwissen wertvoll sein, etwa durch ein spezialisiertes Business Intelligence Consulting.
Die folgende Tabelle fasst die idealen Einsatzgebiete beider Technologien prägnant zusammen.
Diese Übersicht verdeutlicht die Stärken jeder Technologie in der Praxis.
Diese Gegenüberstellung zeigt deutlich: Die Wahl hängt stark von der Priorität ab – ob Kosten und Speichermenge oder Geschwindigkeit und Interaktivität im Vordergrund stehen.
Für viele Unternehmen liegt die beste Strategie nicht in einer Entweder-oder-Entscheidung, sondern in der intelligenten Kombination beider Technologien. Eine moderne und weit verbreitete Hybridarchitektur nutzt Hadoops HDFS als robusten und günstigen Datenspeicher, während Spark als flexible und schnelle Analyse-Engine darauf zugreift.
Dieser Ansatz vereint das Beste aus beiden Welten:
So können Sie Ihre Daten langfristig und sicher in einem zentralen Data Lake aufbewahren, aber gleichzeitig moderne Analyseanwendungen mit der nötigen Performance betreiben. Dies ermöglicht eine schrittweise Modernisierung Ihrer Big-Data-Infrastruktur, ohne bestehende Investitionen komplett abschreiben zu müssen.
Die Wahl zwischen Spark und Hadoop ist mehr als eine reine Technologie-Entscheidung. Sie betrifft das gesamte Ökosystem – also die Community, verfügbare Tools und die Fachkräfte, die man dafür findet. Diese Faktoren sind oft entscheidender für den langfristigen Erfolg als die reine Performance der Core-Engine.
Hadoop bringt ein über Jahre gewachsenes, extrem reifes Ökosystem mit. Es ist eine komplette Plattform, deren Werkzeuge sich im Enterprise-Umfeld bewährt haben. Anbieter wie Cloudera haben hier eine massive Kundenbasis und bieten umfassenden Support.
Die große Stärke von Hadoops Ökosystem ist seine enorme Vielfalt. Für fast jedes Big-Data-Problem findet sich eine spezialisierte, ausgereifte Lösung.
Dieser modulare Aufbau bietet enorme Flexibilität, erhöht aber auch die Komplexität. Jedes Tool muss gelernt, konfiguriert und gewartet werden.
"Hadoops Ökosystem ist wie ein riesiger Werkzeugkasten. Für viele Aufgaben gibt es ein Spezialwerkzeug, aber man muss auch wissen, welches man wann braucht und wie man es bedient."
Dieser Entscheidungsbaum illustriert, wie Faktoren wie Latenz, Datenvolumen und Budget die Wahl zwischen Spark und Hadoop lenken.
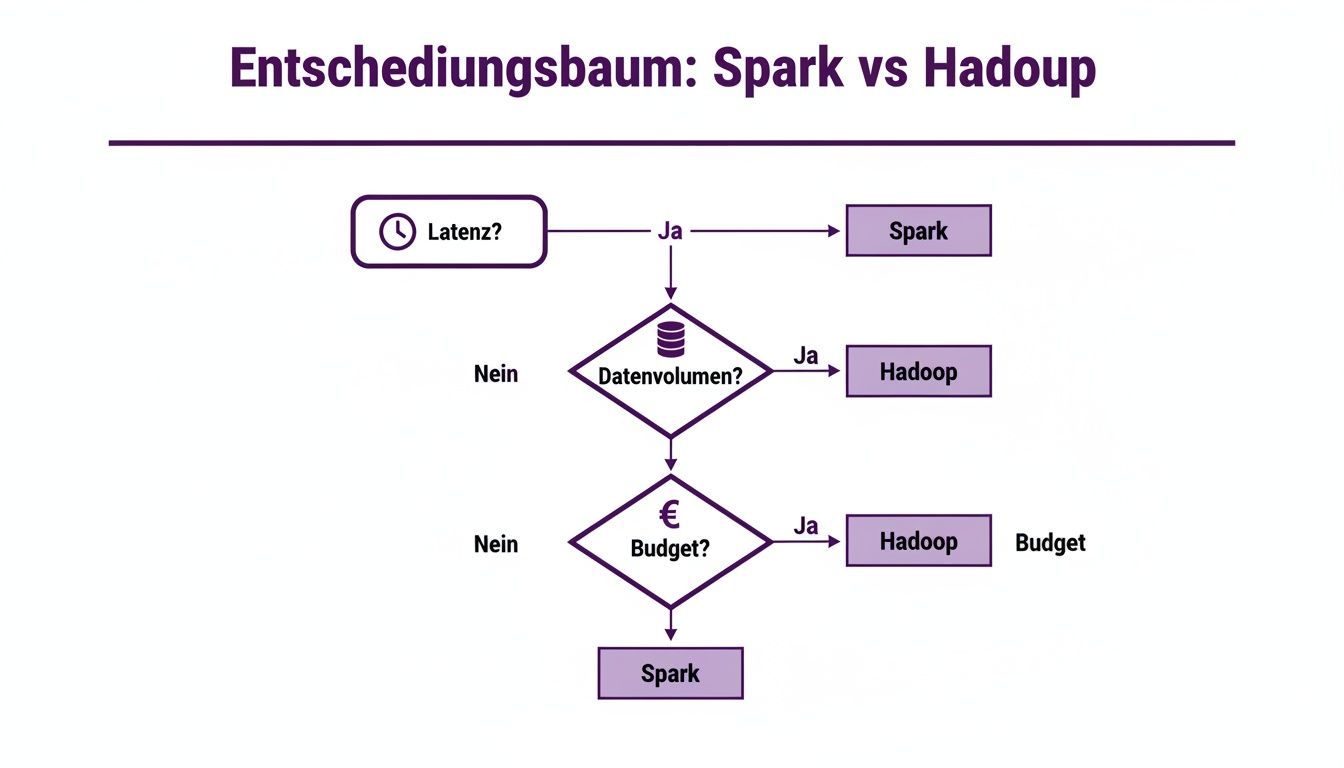
Man sieht sofort: Spark ist die erste Wahl, wenn es um geringe Latenz und komplexe Analysen geht. Hadoop hingegen spielt seine Stärken bei riesigen Datenmengen und kostenoptimierter Batch-Verarbeitung voll aus.
Spark verfolgt einen anderen Ansatz. Statt eines Sammelsuriums an Einzellösungen bietet es ein einheitliches, schlankes Ökosystem. Die Kernkomponenten sind nahtlos miteinander verzahnt und nutzen eine gemeinsame API – ein großer Vorteil für die Entwicklung.
Dieser integrierte Ansatz macht die Entwicklung nicht nur schneller, sondern auch einfacher. Entwickler müssen sich nicht in verschiedene Frameworks einarbeiten, sondern können mit einem einzigen Programmiermodell Batch-Jobs, Streaming-Anwendungen und Machine-Learning-Pipelines erstellen.
Die Community von Spark ist extrem aktiv und die Weiterentwicklung rasant. Spark wird zudem immer mehr zur Kernkomponente in Cloud-nativen Architekturen, wo es oft direkt auf Objektspeichern wie S3 läuft und kaum noch eine Abhängigkeit zu HDFS besteht. Wer tiefer einsteigen möchte, was Cloud-nativ eigentlich bedeutet, findet in unserem Artikel eine gute Erklärung.
Was die Verfügbarkeit von Fachkräften angeht, hat Spark inzwischen nicht nur aufgeholt, sondern Hadoop in vielen Bereichen überholt. Die Unterstützung moderner Sprachen wie Python und Scala macht es für Entwickler attraktiver. Die Entscheidung zwischen Spark vs. Hadoop ist damit auch eine strategische Wette auf die Zukunftssicherheit des eigenen Tech-Stacks und die Fähigkeit, die richtigen Talente zu gewinnen.
Nachdem wir Architektur, Performance und Anwendungsfälle beleuchtet haben, geht es um die konkrete Umsetzung. Wie treffen Sie die richtige Entscheidung für Ihr Projekt? Selten lautet die Antwort schlicht „Spark oder Hadoop“. Vielmehr geht es darum, die passende Architektur für Ihre spezifischen Anforderungen zu entwerfen.
Die folgenden Fragen helfen Ihnen dabei, Ihre Situation zu analysieren und die Weichen richtig zu stellen.
"Für die meisten modernen Big-Data-Projekte hat sich eine hybride Architektur bewährt. Nutzen Sie HDFS für die kostengünstige, skalierbare Speicherung und setzen Sie Spark als performante Analyse-Engine obendrauf. So kombinieren Sie das Beste aus beiden Welten."
Unternehmen, die bereits eine Hadoop-Infrastruktur betreiben, müssen nicht alles über Bord werfen. Eine schrittweise Migration ist der pragmatischste Weg. Beginnen Sie damit, neue Analyse-Workloads direkt in Spark zu implementieren, während Sie HDFS als Speicherschicht beibehalten.
Bestehende, kritische MapReduce-Jobs können dann nach und nach in Spark-Anwendungen umgeschrieben werden. Ein guter Startpunkt sind Jobs, die am stärksten von der höheren Geschwindigkeit profitieren.
Die Debatte „Spark vs. Hadoop“ verschiebt sich zunehmend in die Cloud. Spark emanzipiert sich immer mehr von HDFS und läuft heute oft direkt auf Cloud-Objektspeichern wie Amazon S3 oder Azure Blob Storage.
Diese Entkopplung von Rechenleistung und Speicher schafft eine enorme Flexibilität und Skalierbarkeit – ein entscheidender Vorteil für agile Unternehmen, die ihre Kosten und Ressourcen dynamisch anpassen wollen.
Absolut. Spark ist ein eigenständiges Framework und funktioniert auch ohne Hadoop. Es kann mit verschiedensten Speichersystemen zusammenarbeiten:
Die Kombination mit HDFS ist zwar bewährt und weitverbreitet, aber längst keine technische Notwendigkeit mehr. Moderne, cloud-native Architekturen setzen oft komplett auf Spark in Verbindung mit Objektspeichern wie S3.
Die Kostenfrage lässt sich nicht pauschal beantworten, sie hängt stark vom konkreten Anwendungsfall ab. Wenn es rein um die Hardwarekosten für die Speicherung geht, hat Hadoop oft die Nase vorn. Es wurde dafür konzipiert, auf günstiger Standardhardware mit weniger Arbeitsspeicher (RAM) zu laufen, da es primär festplattenbasiert arbeitet.
Spark hingegen braucht für seine hohe Performance deutlich mehr RAM, was die anfänglichen Hardwarekosten in die Höhe treiben kann. Betrachtet man aber die Gesamtkosten (Total Cost of Ownership), dreht sich das Bild oft: Durch schnellere Entwicklungszyklen und eine effizientere Ressourcennutzung bei rechenintensiven Jobs kann Spark am Ende die wirtschaftlichere Lösung sein. Kürzere Rechenzeiten bedeuten schließlich geringere Betriebskosten und schnellere Ergebnisse.
Benötigen Sie erfahrene Entwickler, um Ihre Big-Data-Architektur zu skalieren? PandaNerds vermittelt Ihnen sorgfältig geprüfte Senior-Entwickler aus unserem internationalen Netzwerk, die sich nahtlos in Ihr Team integrieren. Erfahren Sie, wie wir Ihre technischen Kapazitäten flexibel und kosteneffizient erweitern können: https://www.pandanerds.com.































































































.svg)


