.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Bei der Big-Data-Analyse geht es darum, aus riesigen und komplexen Datensätzen wertvolle Erkenntnisse zu gewinnen, die mit klassischen Methoden unsichtbar bleiben würden. Ziel ist es, Muster, Trends und Zusammenhänge aufzudecken, um fundierte, strategische Geschäftsentscheidungen zu treffen.
Der Begriff „Big Data“ beschreibt eine reale technische und geschäftliche Herausforderung. Stellen Sie sich Big Data wie ein riesiges, chaotisches Lagerhaus vor. Es ist gefüllt mit unzähligen Paketen unterschiedlichster Größe, Form und Beschriftung – von strukturierten Datenbankeinträgen bis zu unstrukturierten Social-Media-Kommentaren oder Sensordaten.

Die Big-Data-Analyse ist der systematische Prozess, dieses Lager zu organisieren. Sie ist die Methode, um die wertvollsten „Pakete“ zu finden, ihren Inhalt zu verstehen und ihn so zu nutzen, dass die Logistik, der Warenfluss und letztlich das gesamte Geschäft optimiert werden. Ohne eine durchdachte Analyse bleibt das Lager eine Ansammlung von Kosten und ungenutztem Potenzial.
Die Dimensionen von Big Data werden oft durch die „fünf Vs“ beschrieben. Für technische Entscheider sind dies keine akademischen Begriffe, sondern konkrete betriebliche Herausforderungen:
Eine durchdachte Analyse-Strategie verwandelt Rohdaten von einer betrieblichen Belastung in ein strategisches Asset. Sie ist ein Werkzeug, um Wettbewerbsvorteile zu sichern.
Dieses Potenzial spiegelt sich im Marktwachstum wider. Der globale Markt für Big Data und Business Analytics, der 2025 ein Volumen von über 309,68 Milliarden US-Dollar hatte, wird bis 2035 voraussichtlich auf 970,44 Milliarden US-Dollar anwachsen. Mehr zur Marktentwicklung erfahren Sie auf researchnester.com.
Die Architektur ist das Fundament jedes Big-Data-Projekts. Eine falsche Wahl führt schnell zu hohen Kosten, schlechter Performance und Datensilos. Daher ist es entscheidend, von Anfang an eine Architektur zu wählen, die nicht nur zu den aktuellen, sondern auch zu zukünftigen Zielen passt.
Bevor wir uns Speicherlösungen ansehen, müssen wir zwei grundlegende Verarbeitungsmodelle verstehen. Sie bestimmen, wie und wann Ihre Big-Data-Analyse stattfindet.
Ein Data Warehouse ist wie eine sorgfältig kuratierte Bibliothek. Es speichert große Mengen an strukturierten, bereinigten und aufbereiteten Daten aus Quellen wie CRM- oder ERP-Systemen. Alles ist darauf optimiert, dass Business-Intelligence-Tools schnelle und wiederkehrende Abfragen durchführen können.
Ein Data Warehouse ist die erste Wahl, wenn Sie klar definierte Geschäftsfragen mit historischen Daten beantworten wollen. Es ist das Rückgrat des klassischen Reportings und der BI-Analyse.
Der Nachteil ist die geringe Flexibilität. Für unstrukturierte Daten (wie Social-Media-Feeds) oder explorative Analysen durch Data Scientists ist es weniger geeignet, da die Datenstruktur (das Schema) von vornherein feststeht.
Ein Data Lake ist wie ein großer Wasserspeicher, in den alle Daten in ihrem Rohformat fließen – egal ob strukturiert, semi-strukturiert oder unstrukturiert. Es gibt kein vordefiniertes Schema; die Struktur wird erst bei der Analyse festgelegt (Schema-on-Read).
Diese Flexibilität macht den Data Lake zum idealen Umfeld für Data Scientists, die experimentieren und neue Muster in unerschlossenen Daten finden möchten. Der Nachteil: Ohne strikte Daten-Governance kann ein Data Lake schnell zu einem unübersichtlichen „Datensumpf“ verkommen. Auch die Performance bei typischen BI-Abfragen ist oft schwächer als bei einem spezialisierten Warehouse.
Das Data Lakehouse ist ein moderner Ansatz, der die Flexibilität eines Data Lake mit den Management- und Abfragefunktionen eines Data Warehouse kombiniert. Es baut auf kostengünstigem Objektspeicher auf, legt aber eine Transaktionsschicht darüber. Diese Schicht sichert Datenqualität und Konsistenz (ACID-Transaktionen).
Ein Data Lakehouse ermöglicht es BI-Analysten und Data Scientists, auf derselben Datenbasis zu arbeiten. Das vermeidet redundante Datenhaltung und aufwendige ETL-Prozesse. Es ist eine zukunftssichere Lösung für Unternehmen, die eine breite Palette von Analyseanforderungen abdecken müssen – von standardisierten Berichten bis hin zu fortschrittlichem Machine Learning.
Viele dieser modernen Architekturen setzen auf Cloud-Technologien. Wie diese im Kern funktionieren, erklären wir in unserem Artikel, der aufzeigt, was die Cloud eigentlich ist. Die Wahl der Architektur hängt direkt von Ihren Zielen ab: Benötigen Sie strukturierte Berichte, rohe Flexibilität oder einen hybriden Ansatz?
Die folgende Tabelle fasst die wichtigsten Unterschiede zusammen und bietet eine Entscheidungsgrundlage.
Diese Gegenüberstellung macht deutlich, dass es nicht die eine perfekte Lösung gibt. Die Entscheidung für ein Data Warehouse, einen Data Lake oder ein Data Lakehouse sollte immer auf einer Analyse der eigenen Anforderungen, des Teams und der langfristigen Unternehmensstrategie basieren.
Eine stabile Datenpipeline ist das Rückgrat jeder Big-Data-Analyse. Sie ist die unsichtbare Infrastruktur, die Daten zuverlässig von ihrem Entstehungsort bis zum fertigen Insight transportiert. Ohne eine durchdachte Pipeline bleiben selbst die besten Analyse-Architekturen Theorie.
Stellen Sie sich das Ganze wie ein automatisiertes Fördersystem in einer Fabrik vor. Rohmaterialien (Daten) werden an verschiedenen Stationen (Quellen) eingesammelt, durchlaufen Verarbeitungsschritte (Transformation) und werden zum fertigen Produkt (analysebereite Daten) zusammengefügt. Dieses Endprodukt landet dann in einem Lager (Data Warehouse oder Lake), bereit für die weitere Verwendung.
Jede Pipeline lässt sich in vier logische Phasen gliedern, am Beispiel einer SaaS-Anwendung, die Nutzerinteraktionen auswertet:
Die weltweit erzeugte Datenmenge wächst exponentiell. Bis Ende 2025 wird das globale Datenvolumen voraussichtlich 181 Zettabyte erreichen. Mehr zu diesen Prognosen finden Sie in diesem Fortune Business Insights Bericht.
Traditionell folgte die Datenverarbeitung dem ETL-Ansatz (Extract, Transform, Load). Daten wurden aus der Quelle extrahiert, vor dem Laden in das Zielsystem (meist ein Data Warehouse) transformiert und dann geladen. Dieser Prozess ist oft starr und langsam, da Transformationen vorab exakt definiert werden müssen.
In modernen Cloud-Architekturen hat sich der ELT-Ansatz (Extract, Load, Transform) durchgesetzt.
Beim ELT-Modell werden Rohdaten direkt nach der Extraktion in einen skalierbaren Cloud-Speicher wie einen Data Lake oder ein Data Lakehouse geladen. Die Transformation findet erst nach dem Laden direkt im Zielsystem statt.
Dieser Paradigmenwechsel bringt entscheidende Vorteile:
Die folgende Infografik hilft bei der Entscheidung, welcher Architekturansatz für Ihre Anforderungen am besten geeignet ist.
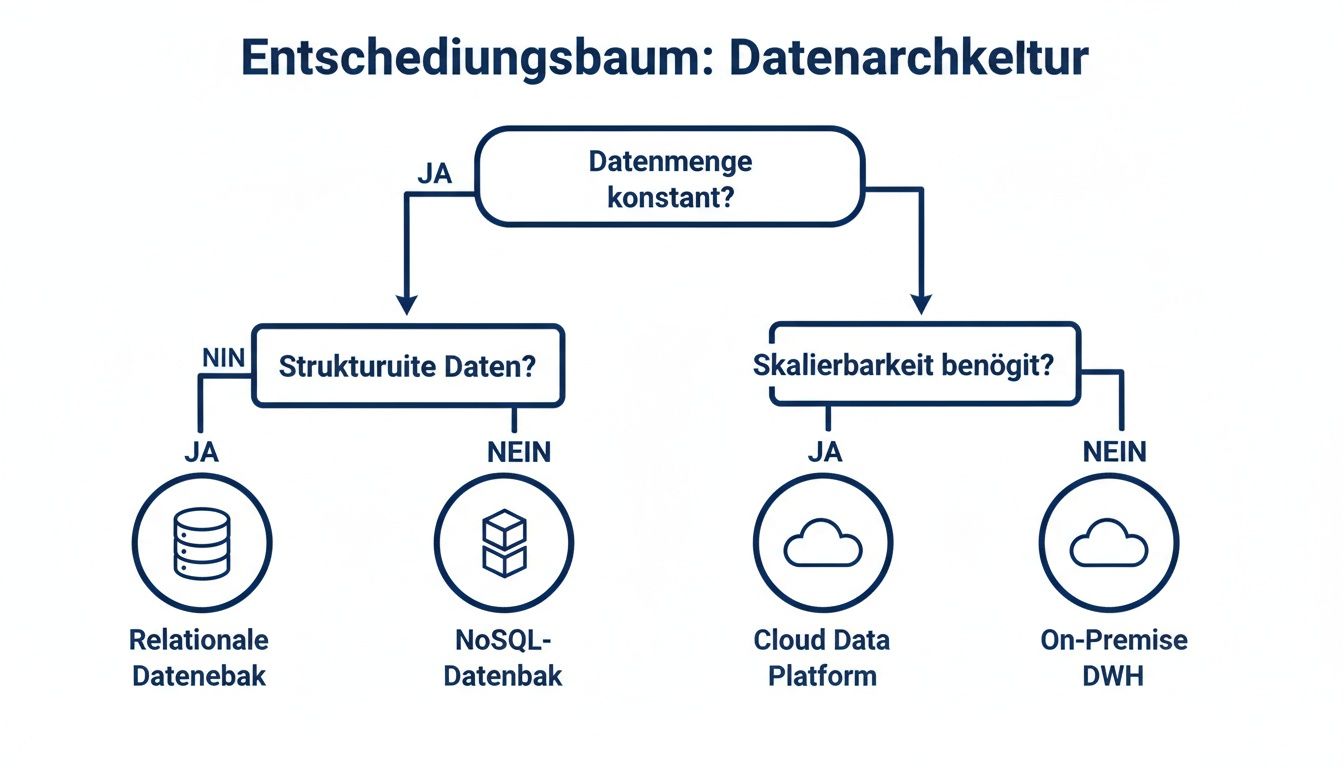
Wie die Grafik zeigt, hängt die Wahl vom Anwendungsfall ab. Hochstrukturierte, wiederkehrende Analysen passen gut zu einem Warehouse-Ansatz (ETL). Explorative Analysen und Machine Learning profitieren von der Flexibilität eines Lake oder Lakehouse (ELT).
Zwei kritische, aber oft vernachlässigte Aspekte sind Orchestrierung und Datenqualität.
Orchestrierung steuert die einzelnen Schritte der Pipeline, managt Abhängigkeiten und fängt Fehler ab. Tools wie Apache Airflow oder AWS Step Functions erlauben es, komplexe Workflows als Code zu definieren (sogenannte DAGs – Directed Acyclic Graphs). Das macht den gesamten Prozess transparent, wartbar und zuverlässig.
Datenqualitäts-Checks sollten ein fester Bestandteil jeder Pipeline sein. Automatisierte Tests können sicherstellen, dass die Daten vollständig, konsistent und plausibel sind, bevor sie die Analyse beeinflussen. Fehlende oder falsche Daten führen schnell zu gravierenden Fehlentscheidungen.
Daten zu sammeln ist die eine Sache. Der wahre Wert von Big Data entsteht erst, wenn man die richtigen Fragen stellt und die passenden Analysemethoden anwendet. Ein riesiger Datenhaufen allein bringt keinen Geschäftsvorteil – erst die gezielte Analyse verwandelt ihn in ein Asset.
In der Praxis hat sich ein Reifegradmodell für die Datenanalyse etabliert, das aus vier aufeinander aufbauenden Stufen besteht. Jede Stufe beantwortet eine grundlegend andere Frage.
Alles beginnt hier. Die deskriptive Analyse schafft einen klaren Blick auf die Vergangenheit. Sie fasst historische Daten zusammen, um zu verstehen, was war. Hier geht es darum, Fakten zu schaffen und den Status quo zu erfassen.
Ein E-Commerce-Shop könnte beispielsweise auswerten, welche Produkte im letzten Quartal die Bestseller waren oder aus welchen Regionen die meisten Kunden kamen. Das geschieht oft durch simple Aggregationen, die in Dashboards und Reports visualisiert werden.
Sobald klar ist, was passiert ist, folgt die Frage: Warum? Die diagnostische Analyse gräbt tiefer und versucht, Ursache-Wirkungs-Zusammenhänge aufzudecken. Sie fahndet gezielt nach Mustern, Anomalien oder Korrelationen.
Zeigt die deskriptive Analyse einen plötzlichen Umsatzeinbruch, würde die diagnostische Analyse untersuchen: Gab es eine Preiserhöhung? Negative Kundenbewertungen? Oder hat ein Wettbewerber eine aggressive Marketingkampagne gestartet?
Jetzt wagen wir den Blick in die Zukunft. Die prädiktive Analyse nutzt historische Daten, statistische Algorithmen und Machine-Learning-Techniken, um wahrscheinliche zukünftige Ereignisse vorherzusagen. Es geht nicht mehr nur um die Vergangenheit, sondern um handfeste Prognosen.
Ein FinTech-Unternehmen könnte damit beispielsweise die Ausfallwahrscheinlichkeit eines Kredits vorhersagen, basierend auf dem bisherigen Zahlungsverhalten. Ein anderes klassisches Beispiel ist die Vorhersage von Kundenabwanderung (Churn Prediction).
Die prädiktive Analyse ermöglicht es, proaktiv zu handeln, statt nur auf Ereignisse zu reagieren. Sie ist der Schlüssel zur Optimierung von Prozessen und zur Antizipation von Marktentwicklungen.
Die präskriptive Analyse ist die Königsdisziplin. Sie geht über die reine Vorhersage hinaus und liefert konkrete Handlungsempfehlungen, um ein bestimmtes Ziel zu erreichen. Sie beantwortet die Frage: „Was ist die beste Aktion, die wir jetzt ergreifen können?“
Aufbauend auf der Churn-Prognose könnte ein präskriptives Modell den optimalen Rabatt vorschlagen, um einen abwanderungsgefährdeten Kunden zu halten – unter Berücksichtigung der Marge. Solche Systeme sind oft das Herzstück von Plattformen, die Fachexperten datengestützte Entscheidungen ermöglichen. Erfahren Sie mehr darüber, wie Self-Service BI Ihr Unternehmen voranbringen kann.
Obwohl prädiktive Analysen im Jahr 2024 mit einem Umsatzanteil von 39,13 Prozent das größte Segment darstellten, weist die präskriptive Analytik das schnellste Wachstum auf. Gerade in Deutschland treiben Branchen wie der Einzelhandel, das Finanzwesen und die Fertigung diese Entwicklung voran. Weitere Einblicke in den deutschen Analytikmarkt finden Sie auf grandviewresearch.com.
In der prädiktiven und präskriptiven Analyse spielt Machine Learning (ML) eine entscheidende Rolle. Im Grunde lassen sich hier zwei Ansätze unterscheiden:
Ein kritischer, oft unterschätzter Erfolgsfaktor ist das Feature Engineering. Das ist die Kunst, aus Rohdaten aussagekräftige Merkmale (Features) zu formen, die ein ML-Modell effektiv nutzen kann. Oft ist die Qualität der Features wichtiger als die Wahl des Algorithmus. Beispielsweise ist das Feature „Anzahl der Logins in den letzten 7 Tagen“ für eine Churn-Analyse wertvoller als der rohe Zeitstempel jedes einzelnen Logins.
Die Auswahl der richtigen Werkzeuge für eine Big-Data-Analyse ist eine Herausforderung. Ein gut durchdachter Tech-Stack ist keine Sammlung von Hype-Technologien, sondern eine pragmatische Kombination von Tools, die Ihre Anforderungen an Skalierbarkeit, Kosten und Leistung erfüllen.

Der Schlüssel liegt darin, den Stack logisch entlang der Datenpipeline aufzubauen und für jede Phase die passende Komponente auszuwählen.
Alles beginnt mit der Speicherung. Cloud-basierte Objektspeicher wie Amazon S3 oder Google Cloud Storage haben sich als Standard etabliert. Sie sind kostengünstig, skalierbar und bilden das Fundament für moderne Architekturen wie Data Lakes und Lakehouses.
Für die Verarbeitung der dort abgelegten Daten sind Frameworks wie Apache Spark führend. Spark meistert sowohl Batch- als auch Streaming-Analysen und erreicht durch seine In-Memory-Verarbeitung eine hohe Geschwindigkeit.
Die Kombination aus einem kostengünstigen Cloud-Speicher für Rohdaten und einem leistungsstarken Verarbeitungs-Framework wie Spark für die Transformation ist das Rückgrat der meisten modernen Big-Data-Stacks.
Sind die Daten verarbeitet, müssen sie für den schnellen Zugriff bereitgestellt werden. Hierfür gibt es keine Einheitslösung, sondern spezialisierte Datenbanksysteme je nach Anwendungsfall:
Die besten Erkenntnisse nützen nichts, wenn sie niemand versteht. Business-Intelligence-(BI)- und Visualisierungs-Tools wie Tableau, Microsoft Power BI oder Amazon QuickSight machen komplexe Daten in interaktiven Dashboards und Berichten verständlich.
Diese Tools verbinden sich direkt mit Ihren Datenquellen und befähigen auch Anwender ohne technischen Hintergrund, Daten selbst zu erkunden. KI-Funktionen, wie sie etwa in Amazon QuickSight zu finden sind, erlauben es Nutzern, Fragen in natürlicher Sprache zu stellen und sofort passende Visualisierungen zu erhalten. Die Wahl des richtigen Tools hängt von der vorhandenen Infrastruktur, den Lizenzkosten und den Bedürfnissen des Teams ab.
Statt sich von Feature-Listen blenden zu lassen, sollten Sie bei der Auswahl jedes Tools drei entscheidende Fragen stellen:
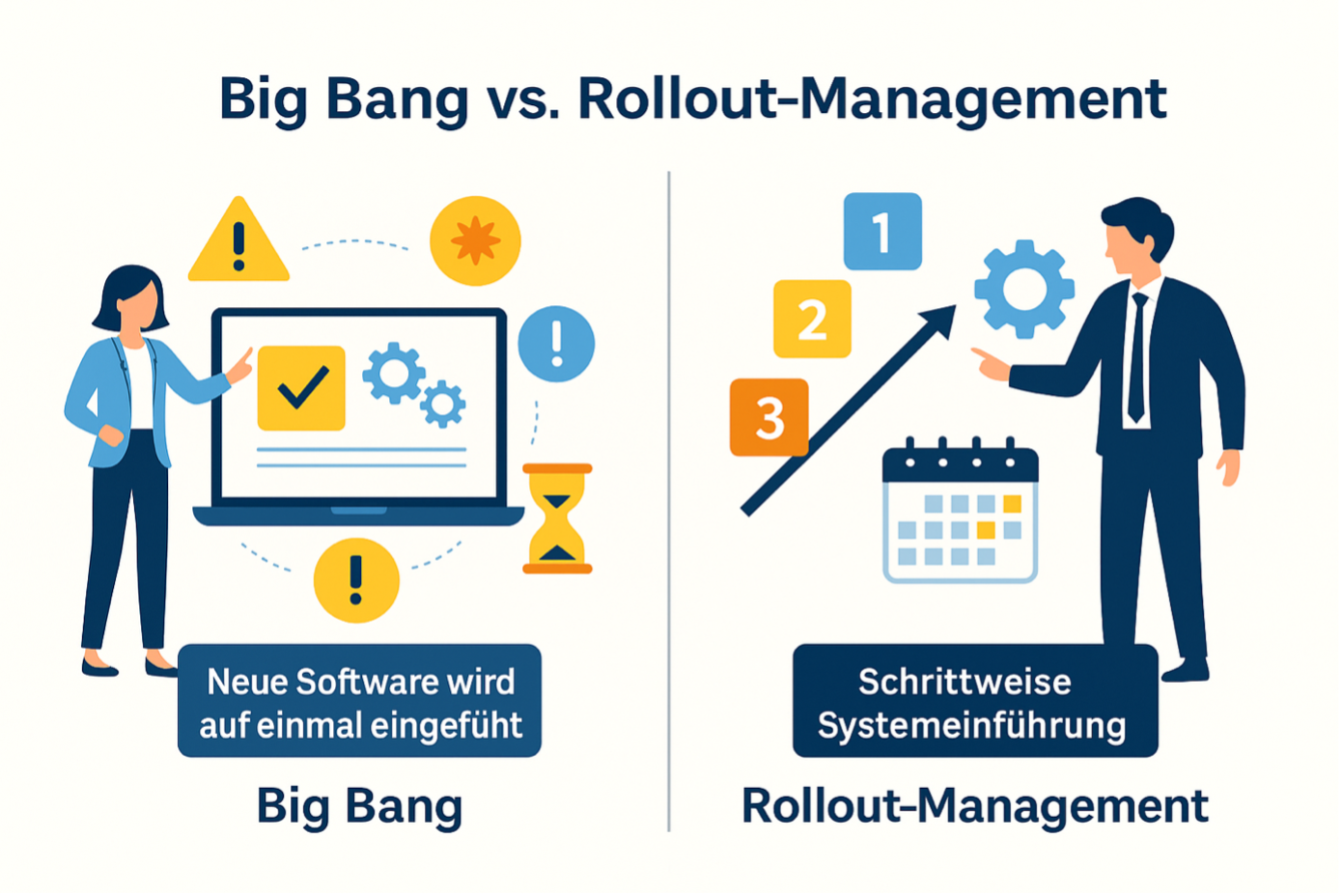
Eine gute Strategie und der passende Tech-Stack sind das Fundament, aber die Umsetzung entscheidet über den Erfolg. Ein Big-Data-Projekt erfordert einen klaren, schrittweisen Plan, um nicht im Sand zu verlaufen.
Der Ansatz sollte nicht ein „Big Bang“-Launch sein, sondern eine agile Reise, die mit einer klaren Zieldefinition beginnt und mit einem schrittweisen Rollout endet.
Bevor Sie in Infrastruktur investieren, muss die Kernfrage beantwortet werden: Funktioniert unsere Idee? Hier kommt der Proof of Concept (PoC) ins Spiel. Ein PoC ist ein kleines, überschaubares Projekt, das beweisen soll, dass die geplante Big-Data-Analyse technisch machbar ist und den erwarteten Geschäftswert liefern kann.
Die wichtigsten Schritte in dieser Phase:
Ein PoC ist kein Prototyp. Sein Ziel ist es, zu lernen und Risiken frühzeitig zu minimieren. Ein gescheiterter PoC ist oft wertvoller als ein teures, gescheitertes Großprojekt.
Nur wenige Unternehmen verfügen intern über das gesamte Spezialwissen für ein komplexes Big-Data-Vorhaben. Wissenslücken, z.B. bei Stream-Processing mit Apache Flink oder dem Aufbau von Lakehouse-Architekturen, können ein Projekt ausbremsen.
Die Zusammenarbeit mit externen Senior-Entwicklern kann hier den entscheidenden Unterschied machen. Modelle wie die Vermittlung hochqualifizierter Entwickler durch PandaNerds ermöglichen einen schnellen und flexiblen Zugriff auf Spezialwissen ohne langfristige Bindung.
Vorteile durch externe Experten:
Für eine reibungslose Integration sind agile Kommunikation und klar definierte Schnittstellen entscheidend. Tägliche Stand-ups, gemeinsame Code-Repositories und ein fester interner Ansprechpartner sind hierfür essenziell. Diese Art der Zusammenarbeit kann auch für die Entwicklung spezifischer KI-Lösungen von großem Vorteil sein. Erfahren Sie in unserem Artikel mehr über pragmatische Ansätze für Künstliche-Intelligenz-Lösungen.
Nach einem erfolgreichen PoC folgt der schrittweise Rollout. Starten Sie mit einer Pilotgruppe oder einem begrenzten Datensatz, anstatt die Lösung sofort im gesamten Unternehmen einzuführen. So können Sie das System unter realen Bedingungen testen und Feedback sammeln.
Der Erfolg eines Big-Data-Projekts muss außerdem laufend gemessen werden. Definieren Sie klare KPIs, die sowohl die technische Leistung (z.B. Abfragezeiten) als auch den Geschäftserfolg (z.B. geringere Abwanderungsrate) abbilden. Nur durch dieses ständige Messen stellen Sie sicher, dass Ihre Big-Data-Analyse zu einem nachhaltigen Motor für messbaren Geschäftswert wird.
Wenn Sie eine Big-Data-Analyse in Erwägung ziehen, tauchen oft dieselben Fragen auf. Hier finden Sie praxisnahe Antworten, um schnell Klarheit für Ihre Entscheidungen zu gewinnen.
Eine pauschale Antwort ist unseriös. Die Kosten hängen stark vom gewählten Architekturmodell, dem Tech-Stack und der Teamgröße ab. Ein Cloud-nativer Ansatz mit Pay-as-you-go-Diensten ist anfangs oft günstiger als der Aufbau einer eigenen On-Premise-Infrastruktur.
Der größte Kostenfaktor ist häufig nicht die Technik, sondern fehlendes Spezialwissen. Externe Senior-Entwickler können eine smarte Lösung sein, um teure Fehler zu vermeiden und das Projekt schneller zum Erfolg zu führen.
Auch die Tiefe der Analyseziele spielt eine Rolle. Ein deskriptives Reporting ist günstiger als ein komplexes prädiktives Modell, das ständiges Training und Monitoring erfordert.
Die Frage nach dem einen besten Tool führt in die Irre. Die richtige Wahl hängt vom Anwendungsfall und Ihrer bestehenden IT-Landschaft ab. Apache Spark ist extrem vielseitig für die Datenverarbeitung, während sich für die Visualisierung Tools wie Tableau oder Power BI etabliert haben.
Statt nach der perfekten All-in-One-Lösung zu suchen, sollten Sie einen modularen Tech-Stack zusammenstellen. Wichtige Entscheidungskriterien sind:
Die Time-to-Value kann variieren. Mit einem agilen Ansatz können Sie jedoch schon nach wenigen Wochen erste Erfolge erzielen. Starten Sie mit einem klar umrissenen Anwendungsfall als Proof of Concept (PoC).
Anstatt monatelang an der perfekten, unternehmensweiten Lösung zu arbeiten, liefert ein PoC schnell greifbare Ergebnisse. Dieser iterative Weg hilft, früh zu lernen, den Kurs anzupassen und den Stakeholdern den Wert des Projekts schnell zu beweisen.
Der Return on Investment (ROI) wird über klar definierte Key Performance Indicators (KPIs) gemessen, die direkt an Ihre Geschäftsziele geknüpft sind.
Beispiele für messbare KPIs:
Die ROI-Messung ist ein laufender Prozess. Regelmäßige Auswertungen machen den Erfolg Ihrer Big-Data-Analyse transparent und schaffen eine solide Basis für zukünftige Investitionen.
Benötigen Sie spezialisierte Senior-Entwickler, um Ihre Big-Data-Projekte voranzutreiben oder Wissenslücken zu schließen? PandaNerds vermittelt Ihnen sorgfältig geprüfte Experten, die sich nahtlos in Ihr Team integrieren und sofort Mehrwert schaffen. Besuchen Sie uns auf https://www.pandanerds.com und erfahren Sie, wie wir Ihre technischen Kapazitäten flexibel und kosteneffizient skalieren können.































































































.svg)


